




ABSTRACT
Much of military training requires CGI (computer generated imagery) due to the fact that the warfighter is in a ground vehicle or aircraft which moves in multiple degrees of freedom in a virtual world. However, one notable exception to this rule of thumb is a dismounted operator who is “on foot”. Indeed, a large number of engagements occur when a warfighter has dismounted a vehicle.
When approaching the problem of a dismounted soldier, new tools and capabilities become available due to the lack of a virtual viewpoint moving through a virtual world. In fact, the data suggests that in a dismounted soldier training paradigm, video-based simulation can be a more effective training method than CGI.
A highly innovative approach is presented of using green-screen video with the new V-Author™ software tool to create a realistic and interactive training environment that is very different from traditional CGI approaches. This interactive video approach for dismounted soldier training could generate higher realism (photographic quality) simulations at drastically lower scenario development costs, and do both with incredible reductions in time to complete a scenario (scenario development time required measured in hours rather than weeks or months).
Simulation fidelity impact on judgment, psychological and physical skill acquisition and transfer is discussed. Research indicates that higher fidelity simulation can lead to improvement in real world skills. Finally, a formula is proposed for evaluating the potential of improved real world skills on saving human lives in deadly situations that might be faced by dismounted personnel.
INTRODUCTION
This paper describes a new approach to developing high-fidelity scenarios using video (not CGI) to enhance dismounted simulation training. First, we explore a video-based approach that can uniquely be applied to dismounted training. Second, we determine if the use of video would have advantages for higher fidelity training and compare that with CGI, both today and in the future. Third, we explore if higher fidelity simulation training would theoretically result in improved performance in real-world situations. Fourth, a formula is proposed to numerically calculate the estimated net benefit of the potential real-world performance improvements in life and death situations.
A VIDEO-BASED APPROACH FOR DISMOUNTED TRAINING
Static Viewpoint and Dismounted Training
Since the advent of computer graphics, the standard approach for nearly every simulation solution, especially military simulation, is to employ a form of computer-generated imagery (CGI). Advances in computer and graphic power have only served to further entrench CGI as the “go to solution” for simulation. In fact, CGI is so prevalent today, a valid concern is that developers might not “think outside the box” of CGI for potentially superior alternatives especially suited for specific types of training. Of course, the flexibility of CGI to provide visual simulation of a changing viewpoint is highly desirable for such applications as flight simulation, driving simulation and many more, but what if a simulation problem does not require, or even prefer, a changing viewpoint?
One very unique attribute of dismounted simulation training is that the viewpoint of the world needs to be static (non-moving). Instead of the trainee using a steering wheel, gas pedal, joystick or other device to essentially move the virtual world around them, they use their own feet and body to move around the physical world with the virtual world projected on a screen or screens around them. In fact, if the static viewpoint of the virtual world were to suddenly shift in front of a dismounted trainee, it would potentially lead to simulator sickness for the participants (Johnson, 2005, p. 18). This idea of a static viewpoint is the antithesis of standard vehicular simulation where the viewpoint is often moving at varying speed and direction in a virtual world. Multiple trainees are often in a dismounted simulation at the same time and if the world were to shift for only one participant, it would be unsettling for the other participants (Johnson, 2005, p. 18). However, it is possible to show a moving viewpoint, such as transitioning participants from one location to another location during a simulation, but during this transition engagements do not occur until the viewpoint stops moving. When a dismounted simulation training participant is about to engage with a simulated hostile force, if the viewpoint moved at this point in time, it would be tantamount to firing a weapon in the midst of an earthquake and should normally be avoided.
Thus a static viewpoint is not only required, but it is actually preferred for dismounted simulation training. While the static viewpoint might sound like a limitation of dismounted simulation, it does have the advantage of no movement mismatch, and thus avoids simulator sickness for one or even multiple participants (Johnson, 2005, p. 18). Moreover, by removing the requirement of a moving viewpoint the door is open to explore the use of other solutions, such as the use of video.
Limitations of Previous Video-Based Solutions
In order to utilize video effectively for the purpose of dismounted training, there must be a method to interact with the video. Previously the only method of interacting with video was by using video-branching software whereby the entire video cuts to a pre-determined new video sequence based on some event (such as shooting at a video of a human who poses an immediate threat). There are several limitations with this video-branching approach:
- Reuse – the human characters and the background are captured together and cannot be easily reused.
- One Threat Limit – due to the complexity of filming each branching event, generally there can only be one threat presented on the screen at any one time.
- Limited Interaction – the amount and variety of interaction is very limited, since any interaction must be recorded as a complete video sequence at the location and time of original filming.
- Cut, Paste, and Modify – not able to cut, paste or modify backgrounds, individual characters, or props in a scenario or to move them between different scenarios.
- Adding New Characters and Backgrounds – not easily able to add new characters or new backgrounds.
A New Video-Based Solution for Dismounted Training
During the 2012 I/ITSEC tradeshow an entirely different methodology of utilizing video effectively for dismounted training was unveiled, called “V-Author™”. First, a background image is captured, added to the library and can then be simply dragged and dropped into V-Author (see Figure 1). The background image can be captured in various ways, such as a standard digital camera or even a camera phone, enabling geo-specific training. The background image can even be a panoramic image so that you can select one particular area for single-screen training or use the whole image for training across multiple screens, simultaneously.
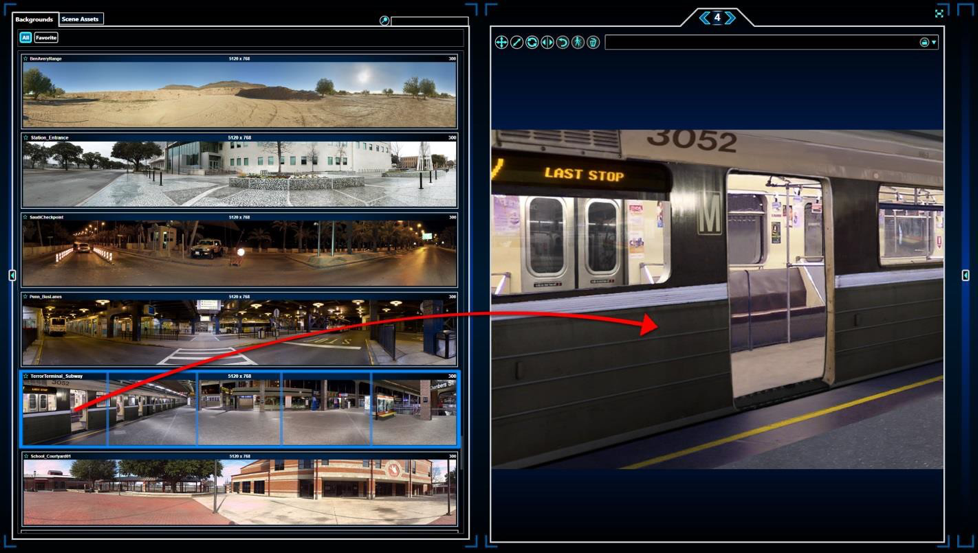
Once the background image is captured it is possible to create the illusion of depth by defining regions, such as doors or windows. Once these regions are defined, a task that might take only a few minutes, you have completed the work needed on the background image and it can be saved to the library. Imagine if a warfighter takes a picture of an area where they think they will have to engage the enemy and then in a matter of minutes can have the image of the area ready to insert into any simulator for training.
For most simulation users, the included library of over 100 building blocks, such as backgrounds, characters and props are

more than adequate for their training needs. However, in a worst case scenario, let’s imagine that enemy tactics have changed and so we need to create a new human character and do so quickly. In this case, a person is filmed on green-screen performing whatever tasks are required (see image to the right). Also, any planned interactions are also filmed, such as the person giving up, firing weapon, or being shot themselves. The various segments are then labeled (giving up, firing weapon, shot) and triggers can be assigned to each segment. In the V-Author software, the new character can be dropped onto any background and combined with any other character from the library to create training material to counter the new enemy tactic (see image below). Using V-Author, a new scenario for countering new enemy tactics could be developed by personnel with average video production skills (no computer graphic skills required) and ready for deployment in potentially a few hours of receipt of the details of the new enemy tactic. To demonstrate the speed of scenario development, V-Author was used at the 2012 I/ITSEC tradeshow to create a fully interactive scenario of an attack on the entrance to the tradeshow, which was ready for full simulation training on the first day of the tradeshow.
Additionally, layers can be applied to the background image, so that a character can be positioned ‘behind’ a door (notice part of the man is hidden behind the door of the background image in the image below.

V- Author has many advantages over a traditional video branching approach, such as:
- Reuse – the human characters and the backgrounds can be reused.
- Unlimited threats – each character is independent, so the number of threats is not limited to one.
- Unlimited Interaction – each character is independent and can be combined with triggers for nearly any type of interaction required. Many varied interactions can be recorded with a video camera and actor(s).
- Cut, Paste, and Modify – able to cut, paste and modify backgrounds, characters and props.
- Adding New Characters and Backgrounds – backgrounds are simple to add. Adding new characters is very efficient when considering the small effort that yields human characters with high realism.
Video Enables High-Fidelity Human Realism
Video has the advantage of capturing the details down to the resolution of the camera being used and can capture the most subtle nuance of human non-verbal communication. Recent digital video camera technology can even capture and replay resolution to the point equivalent to the human eye, which if properly captured and displayed would be a perfect match (the highest fidelity possible) to observing a real human in the real world. Video is also very forgiving, even without the best video equipment high-fidelity simulations of humans can be created. An example is shown of video (real-time) as compared to rendered CGI (non-real-time) of the same situation (See Figure 4). A survey of 30 people was conducted using the exact images shown in Figure 4. Of course, the perception of realism is highly subjective to each person, although that subjective perception is precisely our interest. The survey result yielded the following results:

- Video Sample average = 98% Realistic
- CGI Sample average = 39% Realistic
The ability to quickly and affordably capture footage of humans using standard video equipment, with high-fidelity in both look and movement, cannot be matched by any other current technology or approach. The results of the survey seem to indicate that video has inherent realism advantages when compared with CGI humans (See Figure 5).

While the level of fidelity of humans in simulation is of critical importance, the cost required to obtain these high- fidelity human characters is of great concern. Surprisingly, even though video far surpasses the realism of CGI, the average cost of creating a new human character in video is far less, often a tiny fraction of the cost and time to create a similar human character in CGI.
It should be noted that there is a wide variety of video camera technology currently available, with new advances occurring regularly. Since video is designed to capture whatever is within the camera’s view and humans can be easily positioned in front of the camera and told to perform various natural movements, it is apparent that video confers far more realism, and at very low cost, as compared to a CGI approach, at this time.
Limitations of CGI Today and in the Future
There is no doubt that computer technology and CGI fidelity continues to advance at a steady pace. Some might argue that in the future CGI will be able to equal the photorealism of video. This argument usually begins with an enthusiast reminder of how far CGI has advanced in recent years and ends with an assumption that CGI will solve any remaining limitations in short order. However, some suggest that CGI has solved the easier tasks and the remaining problems are the most challenging, in some cases, by orders of magnitude. For CGI to equal the quality of video for human characters, many challenges remain and only three such problems are discussed below.
CGI Human Runtime Problem
One obstacle is the technological limitations to perfectly replicate the look and feel of a human and render this in real-time. To date, computer software takes many shortcuts in order to render scenes as quickly as possible. Yet, when it comes to humans, we are all experts at noticing the smallest details that do not look “normal”, so many of the CGI shortcuts are not possible when it comes to CGI human realism.
In fact, the limitation is not just computational capability; it is also graphic art and animation refinements that make CGI humans look as real as video. The most talented graphic artists, working long hours with non-real-time rendering are just now starting to equal the quality of video. The distance between today and a point in time when CGI humans can match video humans is difficult to predict, but the computing power required might be orders of magnitude beyond our fastest computers. The larger concern is can the industry truly translate computing power advances into more realistic CGI humans for real-time interaction? If the relationship were linear between computing power and CGI human realism for simulation, then CGI humans in simulation today would be twice as realistic as those displayed 18 months ago, so there must be other factors at work than just computing power.
The CGI Human Authoring Problem
A major obstacle is the time and cost of the creation of new CGI characters. The amount of time and skill level of professional artists needed to create a photorealistic human is incredible. In fact, very few computer graphic artists even have the necessary skills to create a photorealistic human in CGI. This means that even if given unlimited time and resources, many graphic artists could never deliver a truly photorealistic human.
It is not enough to create just one photorealistic human. Training scenarios need a variety of different looking humans with the ability to do all types of different things and to do unexpected things in the future. Ideally, the non- technical customer would have the ability to easily add new characters with new movements in the future. A photorealistic CGI human needs natural body movement, correct eye movement and reflection, facial twitches and hundreds of muscle movements that correspond to speech and emotions, just to name a few elements needed to replicate a normal human. The skill needed by the graphic artist or animation specialist to accomplish a natural looking human is extreme. However, it does seem plausible that if industry were able to create one photorealistic real-time human, there might be the ability to reuse some of the work for other human characters. Still tremendous challenges exist to providing an easy to use, CGI-based, authoring environment usable by a non-technical person with real-time output that matches video of a real human.
CGI’s Achilles’ Heel: The Uncanny Valley
“In 1978, the Japanese roboticist Masahiro Mori noticed something interesting: The more humanlike his robots became, the more people were attracted to them, but only up to a point. If an android became too realistic and lifelike, suddenly people were repelled and disgusted. The problem, Mori realized, is in the nature of how we identify with robots. When an android… barely looks human, we cut it a lot of slack. It seems cute. We don’t care that it’s only 50 percent humanlike. But when a robot becomes 99 percent lifelike—so close that it’s almost real—we focus on the missing 1 percent. We notice the slightly slack skin, the absence of a truly human glitter in the eyes. The once-cute robot now looks like an animated corpse. Our warm feelings, which had been rising the more
vivid the robot became, abruptly plunge downward. Mori called this plunge ‘the Uncanny Valley,’ (see Figure 6) the paradoxical point at which a simulation of life becomes so good it’s bad” (Thompson, 2004).
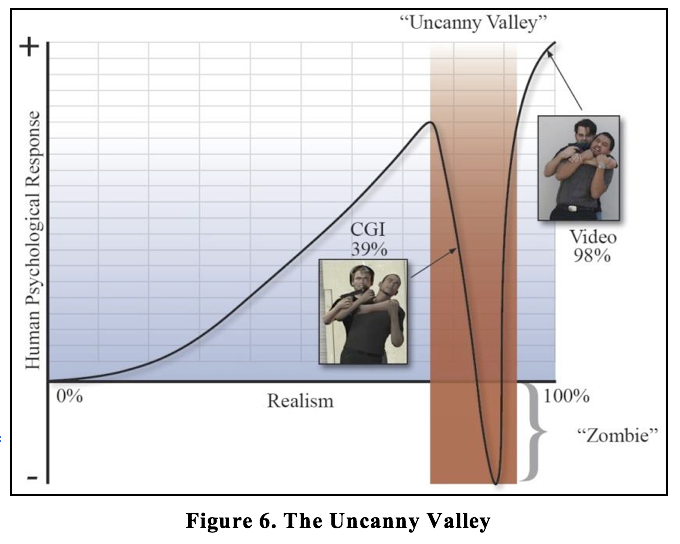
Unfortunately, the task to obtain CGI realism equal to video realism is not only arduous, but often developers land in the Uncanny Valley and then spend tremendous time and money in an unsuccessful attempt to exit the Uncanny Valley. Like quick sand, the more they struggle to exit the Uncanny Valley, the more they are firmly stuck in the valley. The addition of one more element of realism can make a different element look unnatural and so on. An excellent example of the Uncanny Valley is the movie The Polar Express which used state-of -the-art CGI and motion capture technology, but was ultimately called “a failed experiment” by many critics. Paul Clinton from CNN.com echoed the feelings of many, in 2004 when he said “Those human characters in the film come across as downright… well, creepy.” The Polar Express movie cost $165 million for 100 minutes of rendered content. The task is even more daunting when considering that CGI humans must be interactive, rendered in real-time (30 to 60 frames per second) and done on a far more modest budget for simulation training. It is impressive to note that video jumps entirely over the Uncanny Valley, providing realism with today’s technology (see Figure 6).
THE TRAINING EFFECTIVENESS OF HIGH-FIDELITY SIMULATION
Before discussing the training effectiveness of high-fidelity simulation, there are some fundamental training constructs that should be explained. First, from a training design point-of-view, there are two critical and related issues that should be addressed: skill acquisition and skill transfer (Goldstein, 1993). Skill acquisition is defined as learning the knowledge and skills necessary for effective performance. Skill transfer is defined as the transportability of trained knowledge and skills from the training context to the performance environment, and focuses on issues of retention, maintenance, and generalization (Baldwin & Ford, 1988). While both of these issues have importance, skill transfer is the more challenging issue (Barnett & Ceci, 2002).
There are two main approaches for resolving the transfer problem through simulation training design. One approach addresses physical fidelity, whereas the other approach addresses psychological fidelity. The physical fidelity approach focuses on the use of high fidelity simulation for skill acquisition to minimize or eliminate skill degradation during transfer. High fidelity simulation is achieved when the training simulator reproduces, or is a close approximation, of the actual performance environment. The essence of this training strategy is that the emphasis on realism (such as realistic humans during deadly situation training) will minimize differences between the training and performance contexts, thus enhancing the potential for knowledge and skill transfer (Kozlowski & DeShon, 2002). This concept is rooted in the idea of the transfer of learning depending on the proportion to which the learning task and the transfer task are similar (i.e., identical elements theory: Thorndike & Woodworth, 1901). One approach is using high-fidelity simulation training to closely resemble the performance environment so as to maximize skill transfer (Druckman & Bjork, 1991).
The psychological fidelity approach is focused on the extent to which the training environment prompts the essential underlying psychological processes relevant to key performance characteristics in the real-world setting. In other words, it is an effort to evoke the central psychological constructs and mechanisms responsible for the on-the-job performance (Kozlowski & DeShon, 2002).
The two approaches, physical fidelity and psychological fidelity are not competing alternatives, but are absolutely complementary. When coupled together, the psychological fidelity approach can improve the cost-benefit and overall effectiveness of the training system (Kozlowski & DeShon, 2002). Thus, simulation approaches that enhance both physical and psychological fidelity would be the most valuable as it would greatly amplify both skill acquisition and skill transfer.
Three Key Elements of Dismounted Training
Dismounted training can be broken down into three types of skills, these are:
- Judgment – Identify threats and correctly assess their threat level for appropriate use of force
- Psychological – Mental abilities to determine and execute actions to achieve intended outcomes
- Physical – Physically performing the actions with your body and tools (weapon)
These skills are best described in a sample situation of a dismounted operator:
- A threat is suddenly recognized, for example a person in the distance is raising a weapon in the direction of the trainee and the trainee decides there is a threat and that they must engage (judgment)
- The trainee’s mind is shocked and activates fight/flight response, their finger finds the trigger of their weapon, and without thinking, they fire the first round into the ground (psychological)
- The trainee begins to move their weapon toward the threat and often fires a second or third shot before engaging fine motor skills to accurately aim at the threat (physical)
Judgment and Psychological Training
The first critical stage involves all the elements of judgment, such as being aware of a threat and then deciding what to do about the threat. This stage also includes the psychological process of deciding to engage another human with deadly force. Human realism and high-fidelity simulation is of utmost importance for the judgment stage. Notice that the first two elements requiring training are both mental activities: judgment and psychological. The operational environment can be very difficult; trying to determine threats from non-threats often comes down to acute observation of very subtle non-verbal cues. If the operator does not sense danger nor observes a threat, their physical skills have no power to assist. In addition, if the operator makes a judgment error and engages friendly forces or engages non-threats, then the result of effective physical skill could be disastrous. The sample above also includes an example of where the trainee does not initially succeed with the psychological skill. This is not accidental, as it points out a difficult skill to transfer from training to the real-world, where fractions of a second can mean life or death. In all of these situations, it is difficult or impossible to employ CGI characters to recreate these situations with the fidelity level required to provide the subtle human non-verbal cues and precise visual nuances necessary to recreate the majority of potential dismounted training scenarios. Two research studies indicate that on average we place 55% importance on body language, 38% importance on tone of voice and 7% importance on the words spoken (Mehrabian & Wiener, 1967 and Mehrabrian & Ferris, 1967). If over 50% of decision making is based on non-verbal communication, such as body language, then it would naturally follow that high-fidelity simulation should closely replicate human realism to most effectively improve skill acquisition and transfer in the trainees. Research indicates that using high-fidelity simulators leads to mastery learning, also known as “performance accomplishment,” which produces higher performance outcomes (Issenberg et al., 2005; Larew et al., 2006).
These task environments, which can be characterized as dynamic decision making (DDM) situations, place incredible demands on the skills of operators, sometimes suddenly and with life-changing intensity. DDM tasks are dynamic, ambiguous, and emergent. They necessitate rapid assessment of the situation as it unfolds, diagnosis and prioritization of possible actions, and implementation of appropriate task strategies (Kozlowski & DeShon, 2002). DDM tasks place heavy demands on decision makers, requiring high levels of expertise. This higher level of expertise often depends on either experience already gained or access to high-fidelity simulation or other training tools. Critical decisions, such as an operator’s judgments regarding deadly force, literally have life or death consequences.
Physical Training
The final stage is to complete any physical actions that are needed. This would include aiming a weapon correctly, pulling the trigger, and any other required physical actions. Trainees often practice the physical mechanics of shooting until it becomes instinctive. High fidelity in this domain requires the trainee to use a close replica of their weapon (with correct ballistics), in a simulated environment that is a close approximate of the real world just to name a few considerations. When a trainee practices in a simulator they want the muscle memory and skills gained to be valid in the real world and so simulation similarity to the real-world is critical to avoid wasting training time or even worse, the potential of negative training. A trainee that becomes excellent in the physical domain will be able to handle their weapon with expert ease and be able to physically neutralize a threat with speed and accuracy.
IMPORTANCE OF IMPROVED SKILLS IN DEADLY SITUATIONS
If video-based training can provide higher fidelity simulation training, and higher fidelity simulation training can lead to improved real-world skills, then the final task is to determine a numerical value of the benefits. Since a primary goal of dismounted personnel is to accomplish their mission, protect the lives of both themselves and allied forces, while neutralizing hostile threats – the benefit of improved skills can be measured in a reduced amount of allied and innocent casualties per lethal engagement. We can model this by introducing the following definitions for skill values:
Probability threats and their threat levels are properly assessed (Judgment Skill)
Probability the correct actions are determined to achieve an intended outcome (Psychological Skill)
Probability physical actions are correctly performed to achieve an intended outcome (Physical Skill)
For a potentially lethal encounter, four outcomes are considered:
- The threat surrenders with no casualties incurred
- The threat is killed or incapacitated by the trainee
- The threat kills or incapacitates the trainee
- The trainee misapplies deadly force and kills or incapacitates a non-lethal threat
The probability that a threat will surrender can be modeled by:
(1)
Where TCL is the Threat Compliance Level defined as the probability the given threat will surrender given perfect judgment and psychological skills. Often, the most desirable outcome of a lethal encounter is for the threat to peacefully surrender as no casualties are incurred. In this unique situation, judgment and psychological skills are the most critical (see Equation 1). For the remainder of this analysis we will only consider TCL values of 0, meaning there is no chance of surrender, so the only outcomes are the threat is neutralized by the trainee or the trainee is killed or incapacitated by the threat. The probability the trainee creates a favorable outcome is shown in Equation 2.
(2)
All three skills of judgment, psychological and physical combine to determine the probability of a favorable outcome for the trainee. The probability the trainee is killed or incapacitated by the threat is the complement of this probability (see Equation 3).
(3)
Thus, anything that increases all three areas of skill will serve to reduce the probability of a trainee becoming a casualty in a lethal encounter.
We can also construct a model for how these skill levels affect Mistake-of-Fact shootings. A Mistake-of-Fact shooting can be a friendly fire incident, shooting of innocents or misapplication of deadly force against non-lethal threats. A Mistake-of-Fact shooting is modeled as a failure of judgment followed by lethal application of psychological and physical skills (see Equation 4).
(4)
This model illustrates that improving psychological and physical skills without addressing judgment skills can actually increase the probability of a lethal Mistake-of-Fact shooting.
The goal of effective training is usually to reduce the probability of undesirable outcomes as much as possible. It is instructive to look at the effects from improving skills on the number of undesirable outcomes per 100 lethal encounters with this model. For these models, perfect skill level is 100% and a complete lack of skill is 0%. If baseline entry level skills are 80% for judgment, 80% psychological and 80% physical skills, this gives the beginner trainee an almost 50/50 shot at eliminating the threat in a lethal encounter and coming out unscathed. At 80% for all three skills, the model predicts about 49 trainee casualties and 13 Mistake-of-Fact shootings for a total of 62 undesirable outcomes per 100 lethal encounters. If physical skills improve to 90% without improving any other skills, the 10% increase of physical skill reduces trainee casualties to 42 but also increases Mistake-of-Fact shootings to 14 per 100 lethal encounters. The 10% improved physical skill reduces overall casualties by six but increases Mistake-of-Fact casualties by one. On the other hand, if judgment skills are improved from 80% to 90%
(.9) while other skills remained at 80%, then trainee casualties are again reduced to 42 but Mistake-of-Fact shootings plummet to six reducing overall casualties by 14 per 100 encounters. These results are summarized in the following table:

These formulas show how critical it is for the dismounted operator to have near perfect skills. Moreover, it clearly demonstrates that for the maximum benefit for the operator and the community, the most important skill is judgment. It also demonstrates that with good judgment comes the need for both excellent psychological and physical skills to effectively carry out the correct decision. Excellent judgment normally emerges from experience and the safest way to gain relevant experience is from high-fidelity practice of deadly situations, while having the ability to learn from each encounter without deadly consequences of any mistakes during training.
CONCLUSION
It appears that simulation training for a dismounted soldier can be effectively enhanced through the use of video- based solutions that avoid some of the limitations of human realism currently experienced with CGI technology. Computer, memory and graphic adapter advances have greatly enhanced the capability of using video-based characters for dismounted training without waiting for potential future advances that might permit photorealistic CGI humans.
A highly innovative approach was presented of using green-screen video with the new V-Author™ software tool to create a realistic and interactive training environment. This interactive video approach for dismounted soldier training generates higher realism (photographic quality) simulations, at drastically lower scenario development costs, and can do both with incredible reductions in time to complete a scenario (scenario development time measured in hours rather than weeks or months).
Based on the latest technology, video simulation methods are generally far more realistic with humans than CGI (98% realistic versus 39% realistic). Simulation fidelity appears to directly impact Judgment, Psychological and Physical skill acquisition and transfer. Research indicates that higher fidelity simulation can lead to improvement in real world skills. A model was proposed for evaluating the potential reduction of undesirable casualties in deadly situations through improvements in skills. The sheer number of personnel in both military and law enforcement roles who are dismounted (on foot) during a standard day and could face a lethal situation is staggering and deserving of our best efforts to help them effectively enhance skills that are relevant to real world deadly situations.
ACKNOWLEDGEMENTS
The views and conclusions contained in this document are those of the author(s) and should not be interpreted as representing the official position, either expressed or implied, of VirTra Systems, Inc. or of any customer or affiliate of VirTra Systems, Inc. The US Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation hereon.
This work was supported by VirTra Systems, Inc. as part of the company’s mission to advance the training effectiveness of dismounted simulation training.
Special thanks to J.D. Herron who contributed the section entitled, “Importance of Improved Skills in Deadly Situations”, as well as for his major contributions to V-Author™. Also, special thanks to: Wyeth Ridgway, Rob Hill, Chris Lawcock, Matt Burlend, Charles Doty, Richard Kennedy, James Peters, and Brian Overy.
REFERENCES
Baldwin, T. T., & Ford, J. K. (1988). Transfer of training: A review and directions for future research. Personnel Psychology, 41, 63-105.
Barnett, S. M., & Ceci, S. J. (2002). When and where do we apply what we learn? A taxonomy for far transfer.
Psychological Bulletin, 128, 612-637.
Druckman, D., & Bjork, R.A. (1991). In the mind’s eye: Enhancing human performance. Washington, DC: National Academy Press.
Goldstein, I. L. (1993). Training in organizations: Needs assessment, development, and evaluation. Pacific Grove, CA: Brooks/Cole.
Issenberg, S. B., McGaghie, W. C., Petrusa, E. R., Gordon, D. L., & Scalese, R. J. (2005). Features and uses of high- fidelity medical simulations that lead to effective learning: A BEME systematic review. Medical Teacher, 27(1), 10-28. Doi: 10.1080/01421590500046924.
Johnson, David, M. (2005). Introduction to and Review of Simulator Sickness Research. Research Report 1832.
U.S. Army Research Institute for the Behavioral and Social Sciences, 18.
Kozlowski, S. W. J. & DeShon, R.P. (2002). A psychological fidelity approach to simulation-based training: theory, research, and principles. Burlington, VT: Ashgate Publishing.
Larew, C., Lessans, S., Spunt, D., Foster, D., & Covington, B. G. (2006). Application of Benner’s Theory in an Interactive Patient Care Simulation. Nursing Education Perspectives, 27(1), 16-21.
Mehrabian, Albert; Ferris, Susan R. (1967). “Inference of Attitudes from Nonverbal Communication in Two Channels”. Journal of Consulting Psychology, 31 (3): 248–252. Doi: 10.1037/h0024648.
Mehrabian, Albert; Wiener, Morton (1967). “Decoding of Inconsistent Communications”. Journal of Personality and Social Psychology, 6 (1): 109–114. Doi: 10.1037/h0024532.
Thompson, Clive. (2004). The Undead Zone Why Realistic Graphics Make Humans Look Creepy.